
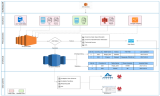

Please find the course details here and the real time case study we'll be doing hands on.
PART 1: Getting started with Spark Core - Programming RDD using Databricks Notebook and later using IntelliJ. Transformation and Action.
Spark_Application->Jobs->Stages->Tasks Architecture
PART 2: Setting up your local environment for Spark - IntelliJ, Scala and SBT. Programming Scala and AWS.
Scala: Basics, Function currying, Higher-order functions, OOPs, Collections, Exception Handling.
PART 3: Dataframe: DSL and Spark SQL, Datasets
Create dataframe from csv, parquet, avro, Functions - withColumn, select, groupBy, agg
Windows and analytics function - rank, dense_rank, lead, lag, etc.
PART 4: Running Spark job on AWS EMR cluster, Automating AWS EMR creation, Spark Job Execution and Terminating Cluster using AWS Lambda
Interpreting DAG on YARN UI and optimizing your Spark job
PART 5: Structured Streaming
Reading and processing streaming data from AWS S3 directories, Kafka Message Queue. Using DSL & Spark SQL on Streaming Dataframe
PART 6: Real time case study
To make things fun and interesting, we will introduce multiple datasets coming from disparate data sources - SFTP Server, AWS RDS - MySQL, Amazon S3, etc. and create an industry standard ETL pipeline to populate a data mart implemented on Amazon Redshift.







