What is Big Data?
Big Data is collection of huge or massive amount of data.We live in data age.And it’s not easy to measure the total volume of data or to manage & process this enormous data. The flood of thisBig Data are coming from different resources.
Such as : New York stock exchange, Facebook, Twitter, AirCraft, Wallmart etc.
Today’s world information is getting doubled after every two years (1.8 times).
And still 80% of data is in unstructured format,which is very difficult to store,process or retrieve. so, we can say all this unstructured data is Big Data.
Why Hadoop is called Future of Information Economy
Hadoop is a Big Data mechanism, which helps to store and process & analysis unstructured data by using any commodity hardware.Hadoop is an open source software framework written in java,which support distributed application.It was introduced by Dough Cutting & Michael J. Cafarellain in mid of 2006.Yahoo is the first commercial user of Hadoop(2008).
Hadoop works on two different generation Hadoop 1.0 & Hadoop 2.0 which, is based on YARN (yet another resource negotatior) architecture.Hadoop named after Dough cutting’s son’s elephant.
Big Data Growth & Future Market
Commercial growth of BIG DATA and HADOOP

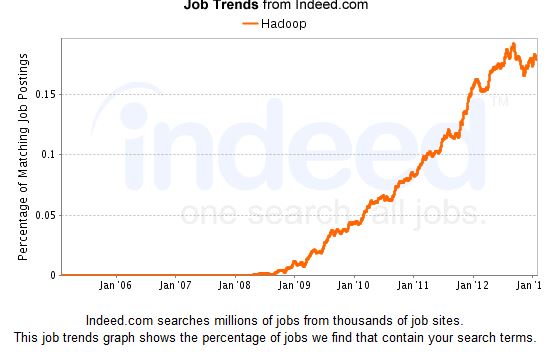
World’s Information is getting doubled after every two years.Today’s market agenda to convert Volume to Value .In current time, every company is investing 30% of its investment to maintain Big Data.According to this, the future prediction by 2020 Data Center is going to be 10X times multiple, Storage Device 100X times multiple,which required to stored this enormousBig Data & to manage this it required massive Man power.The opportunity on Big Data & Hadoop will be 1000X times multiple of today’s requirement by 2020.
IBM is one of the giant user of Big Data.IBM 10% (Million$ 1036)revenue come from Big Data.
Other top five company revenue from Big Data: HP Million$ 664, Teradeta Million$ 435, Dell Million$ 425 ,Oracle Million$ 415, SAP Million$ 368.
Job Titles for Hadoop Professionals
Job opportunities for talented software engineers in fields of Hadoop and Big Data are enormous and profitable. Zest to become proficient and well versed in Hadoop environment is all that is required for a fresher. Having technical experience and proficiency in fields described below can help you move up the ladder to great heights in the IT industry.
Hadoop Architect
A Hadoop Architect is an individual or team of experts who manage penta bytes of data and provide documentation for Hadoop based environments around the globe. An even more crucial role of a Hadoop Architect is to govern administers, managers and manage the best of their efforts as an administrator. Hadoop Architect also needs to govern Hadoop on large cluster. Every HAdoop Architect must have an impeccable experience in Java, MApreduce, Hive, Hbase and Pig.
Hadoop Developer
Hadoop developer is one who has a strong hold on programming languages such as Core Java,SQL jQuery and other scripting languages. Hadoop Developer has to be proficient in writing well optimized codes to manage huge amounts of data. Working knowledge of Hadoop related technologies such as Hive, Hbase, Flume facilitates him in building an exponentially successful career in IT industry.
Hadoop Scientist
Hadoop Scientist or Data Scientist is a more technical term replacing Business Analyst. They are professionals who generate, evaluate, spread and integrate the humongous knowledge gathered and stored in Hadoop environments. Hadoop Scientists need to have an in-depth knowledge and experience in business and data. Proficiency in programming languages such as R, and tools such as SAS and SPSS is always a plus point.
Hadoop Administrator
With colossal sized database systems to be administered, Hadoop Administrator needs to have a profound understanding of designing principals of HAdooop. An extensive knowledge of hardware systems and a strong hold on interpersonal skills is crucial. Having experience in core technologies such as HAdoop MapReduce,Hive,Linux,Java, Database administration helps him always be a forerunner in his field.
Hadoop Engineer
Data Engineers/ Hadoop Enginners are those can create the data-processing jobs and build the distributed MapReduce algorithms for data analysts to utilize. Data Engineers with experience in Java, and C++ will have an edge over others.
Hadoop Analyst
Big Data Hadoop Analysts need to be well versed in tools such as Impala, Hive, Pig and also a sound understanding of application of business intelligence on a massive scale. Hadoop Analysts need to come up with cost efficient breakthroughs that are faster in jumping between silos and migrating data.